

Revisiting - Kafka Partition Rebalancing - Part 1
Deep diving on Kafka Rebalancing Protocol

Introduction
Rebalancing protocol in Kafka consumer is the magic behind how your application could afford to scale. How your application works like magic when a new consumer is added or dies.
All this while your application is running and you're probably sleeping and your pager not troubling you in the middle of the night!
This is my attempt to deep dive with examples of how the new protocol impacts your application.
It is important to understand rebalancing protocol now since some changes are made and you could benefit from it now.
Before we dive deep, Let’s first start by revisiting a few Kafka basics.
Kafka Basics
Kafka is basically a distributed publisher-subscriber platform.
Publisher publishes messages onto “Topics” which are managed by Kafka brokers.
Consumers subscribe to topics to consume messages from Topics.
Consumers for a topic belong to a “Consumer Group”, Every consumer from a group can fetch/process messages from a specific partition of the Topic.
A partition is a unit of parallelism between publisher and consumer.
Producer - A message with the same key is published on the same partition of the topic.
Consumer - One partition is guaranteed to be assigned to only one consumer in a consumer group.
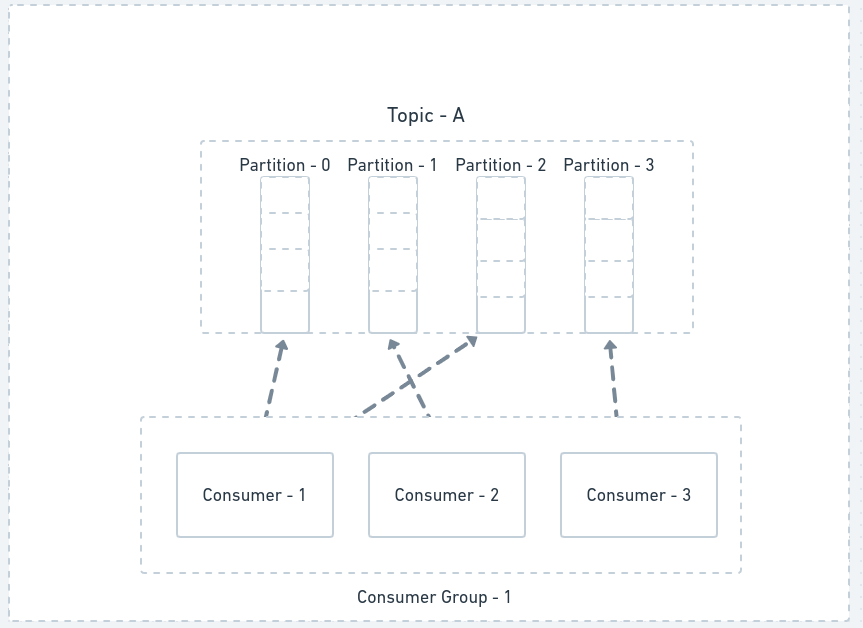
If a consumer leaves the group after a controlled shutdown or crashes or a new one gets added then partitions should be correctly load-balanced amongst the consumers.
This load balancing of partitions between the consumers in a group is called “Rebalancing” and this is achieved using Kafka Rebalance Protocol.
One magical thing with this is there is almost no contribution that Broker has on this rebalance. Let’s dive in and understand how this works!
Kafka Rebalance Protocol
As per kafka documentation
Rebalance/Rebalancing: The procedure that is followed by a number of distributed processes that use Kafka clients and/or the Kafka coordinator to form a common group and distribute a set of resources among the members of the group
This is a standard protocol used in multiple places- Kafka connect/Kafka Streams.
The rebalancing mechanism in Kafka has two parts that form the protocol
Group membership protocol
Client embedded protocol
Group membership protocol - This is for the coordination of members within a group. This is defined using a set of request/response with Kafka broker ( Coordinator)
The second protocol is executed on the client-side and allows extending the first part of the protocol by being embedded in it.
Group Membership Protocol
This protocol has 3 steps that the group members/consumers need to follow.
1.JoinGroup
Consumers send JoinGroup requests after they identify the coordinator broker.
Co-ordinator delays responses until all requests are received as per group.initial.rebalance.delay.ms timeout
The first one to send JoinGroup is selected as Group leader, It receives the list of active members and the selected assignment strategy while others receive an empty response.
The group leader is responsible for executing the partitions assignments locally.
The leader if doesn’t respond in time, there will be another rebalance that the broker can introduce based on session.timeout.ms to receive heartbeat from the leader.
JoinGroup

2.SyncGroup
The second step where the group members syn’s their assignments using sync group request.
The group leader attached the computed assignments while others simply respond with an empty request.
Once the broker replies to all sync group requests, each consumer receives their assigned partitions, invokes the onPartitionsAssignedMethod on the configured listener and, then starts fetching messages.
SyncGroup

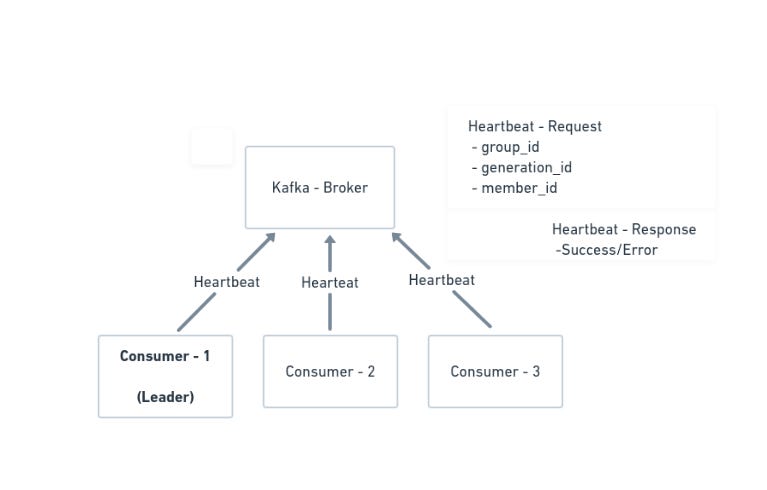
3.Heartbeat
Each consumer periodically sends a heartbeat request to the broker coordinator to keep its session alive (heartbeat.interval.ms).
If a rebalance is in progress, the coordinator uses the “heartbeat” response to indicate to consumers that they need to rejoin the group.
Some negative points of Rebalancing
As you might have guessed, In real life situation hardware can fail. The network or a consumer can have transient failures.
Pods can restart and scaling can happen at runtime introducing new consumers. Unfortunately, for all these situations a rebalance can also be triggered.
Stop the World
Unfortunately all rebalance can not be processed without consumers stopping the processing, causing stop the world effect.
This leads to lag buildup on partitions.
During the entire rebalancing process, i.e. as long as the partitions are not reassigned, consumers no longer process any data. By default, the rebalance timeout is fixed to 5 minutes which can be a very long period during which the increasing consumer lag can become an issue.
Consider that you have 10 consumers in a group that is getting restarted due to a new update.
For a rolling update, Total of 20 rebalances that can happen 10 for new member joining and 10 for old member leaving the group.
So if you have one “pod” that behaves weirdly because of some inconsistent “state” or for GC pause, The complete group goes to rebalancing state and causes issues such as lag buildup.
Especially for Java application, if the group member/pod goes to GC pause or misses a heartbeat, the coordinator will not receive a heartbeat for more than session.timeout.ms milliseconds and considers the consumer dead.
In the next part of this blog, We will see how this is handled in the Kafka version 2.3.0 and why you should move to 2.3.0 for resolving “stop the world” behavior on your processing pipeline.
If you like this article, Do not forget to follow me on Twitter for more such articles.